

作者 | 程茜
编辑 | 漠影
近几年,AI 模型的规模呈数量级增长态势。从 2018 年开始,谷歌发布 BERT,其参数量为 9500 万;2020 年 OpenAI 发布的 GPT-3 模型参数已经扩展到 1750 亿;2021 年 10 月,国内浪潮发布中文 AI 大模型源 1.0,其参数量为 2500 亿;微软和 NVIDIA 联手推出的威震天-图灵(Megatron Turing-NLG)参数规模已超 5000 亿……近四年时间,AI 模型规模增大了 5000 倍之多。
大规模 AI 模型的发展速度已经远远超过摩尔定律,传统数据中心也无法满足 AI 算力需求,传统数据中心向 AI 数据中心转型是大势所趋。
为了满足 AI 模型算力需求,帮助企业构建 AI 数据中心,2021 年 4 月,NVIDIA 推出 DGX SuperPOD 云原生超级计算机,为用户提供一站式 AI 数据中心解决方案,是企业满足 AI 大模型计算的有力武器。
一、模型规模指数级提升,AI 算力需更高性能
2020 年 GPT-3 发布后一度引爆科技圈,国内国外各大科技企业也都在打造自己的大模型,不断扩展 AI 模型的规模边界,并加快技术迭代。
无论是数据规模还是模型规模,近几年来都呈爆发式增长,再加上在自然语言处理、搜索、医疗等领域 AI 应用更加广泛,这也对 AI 算力提出了更大需求,建立多机多卡的大规模集群才能满足更高性能的算力要求。
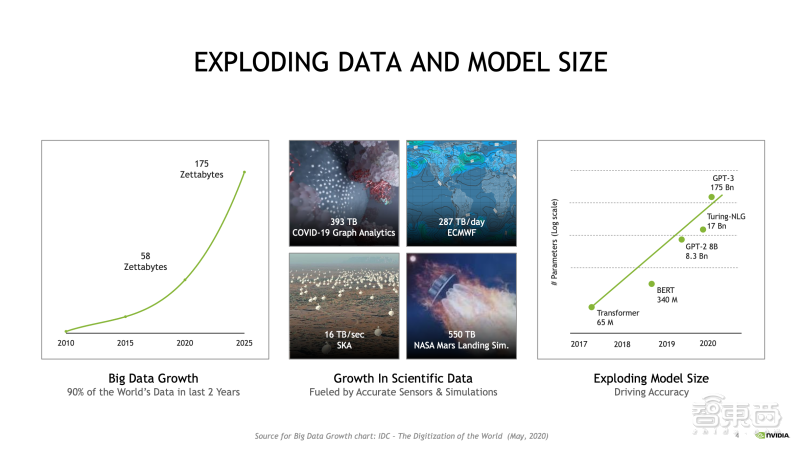
▲数据和模型规模增长示意图
AI 从功能上看主要包括推理和训练阶段,训练过程主要在数据中心完成,对处理器的运算性能要求较高。而传统数据中心开始并不是专门为执行 AI 算法所构建,因此无法满足 AI 模型的算力要求,这也进一步催生了专门针对 AI 训练的现代 AI 数据中心。
AI 数据中心的主流架构是 GPU+CPU 异构架构,CPU 是计算机系统的运算和控制核心,更擅长逻辑控制,不擅长复杂算法运算和处理并行操作;GPU 主要用于支撑大量数据的并行计算,两种处理器相辅相成,能够大幅提升运算效率。
通过 AI 数据中心,融合 AI、云计算、大数据等技术,可以大规模提供算力、提高算力资源利用率、提升数据存储和处理能力,加速大模型 AI 模型的训练和推理效率。
AI 数据中心的发展仍处于起步阶段。NVIDIA 解决方案架构师赵明坤称,企业构建 AI 数据中心需要大量时间、专业知识以及正确的架构方法。因此,那些亟需 AI 转型的企业构建 AI 数据中心的门槛较高,企业需要从软硬件协同、试错成本等多维度综合考量,很难快速搭建起高性能的 AI 集群。

▲AI 数据中心构建难点
二、破解大模型挑战,构建算力+软件一站式解决方案
NVIDIA 推出的 DGX SuperPOD 云原生超级计算机,是一套软硬协同的完整解决方案,在满足 AI 模型算力的基础上,又能帮助企业快速部署 AI 数据中心。
DGX SuperPOD 采用模块化的设计,支持不同规模大小的设计。一个标准的 SuperPOD 由 140 台 DGX A100 GPU 服务器、HDR InfiniBand 200G 网卡和 NVIDIA Quantum QM8790 交换机构建而成,针对超大语言模型预训练这一复杂场景,帮助 AI 研究人员快速搭建一套强大、灵活、高效的系统。

▲NVIDIA DGX SuperPOD
搭载 8 个 NVIDIA A100 Tensor Core GPU 的 DGX A100 服务器,单节点 AI 算力达到 5 PFLOPS,5 个 DGX A100 组成的一个机架,算力就可媲美一个 AI 数据中心。DGX SuperPOD 中,每台 DGX A100 配有 8 个 200Gb/s 的高速计算网,并配有 2 个 200Gb/s 的高速存储网,网络针对 AI 和 HPC 进行了优化,采用计算和存储网络分离的方案,有效避免了带宽增强。
值得一提的是,多个 POD 之间还可以通过核心层交换机直连起来,能够支持多达 560 台 DGX A100 的互连规模。
在软件方面,NVIDIA 集成了基础设施管理软件 Base Command Manager,该软件负责协调 DGX SuperPOD 基础架构上的 AI 模型训练和相关操作,帮助客户同时共享、操作自己的训练任务、计算环境、数据集以及配置任务所需的计算量等。
NVIDIA 还为 DGX SuperPOD 提供专业的部署服务,包括单机系统部署、InfiniBand 网络配置、调度安装调试、监控部署、多机环境、基础性能验证等,从基础系统方面,保证了最快交付。
目前,NVIDIA 的 DGX SuperPOD 方案已经部署到京东探索研究院中,京东探索研究院针对 CV(计算机视觉)、NLP(自然语言处理)、跨模态等领域设计和研发的数十个模型,在 DGX SuperPOD 上达到了比较理想的加速比和扩展性。
NVIDIA 构建的集群方案,化解大模型的算力难关后,能够加速 AI 训练和迭代速度,降低企业 AI 训练的成本,距离普惠 AI 更近一步。